Partitioning mechanism divides a portion of data into multiple streams of rows (one for each node), which is then processed independently by each node in parallel. Each partition of rows is processed separately by the stage/operator. It helps make a benefit of parallel architectures like SMP, MPP, Grid computing and Clusters.
Collecting is the opposite of partitioning. It can be defined as a process of bringing back partitioned data into a single sequential stream (one data partition).
Partitioning Algorithm
As a default, Datastage decides to use between Same or Round Robin partitioning. Typically Same partitioning is used between two parallel stages and round robin is used between a sequential and an EE stage. Datastage supports a few types of Data partitioning algorithm which can be implemented in parallel stages:
- Auto
 Keyed: Rows are distributed based on values in the specified key.
Keyed: Rows are distributed based on values in the specified key.- Hash: rows with same key column (or multiple columns) go to the same partition. Hash is very often used and sometimes improves performance, however it is important to have in mind that hash partitioning does not guarantee load balance and misuse may lead to skew data and poor performance. Hash does not guarantee "continuity": here, 3s are bunched with 0s, not with neighboring value 2. The expensive version of Hash is RANGE, that guarantees continuity.
 - Modulus: data is partitioned on one specified numeric field by calculating modulus against number of partitions. partition = MOD(key_value/#partitions). Faster than Hash. Guarantees that rows with identical key values go in the same partition. Partition size is relatively equal if the data within the key column is evenly distributed.
- Modulus: data is partitioned on one specified numeric field by calculating modulus against number of partitions. partition = MOD(key_value/#partitions). Faster than Hash. Guarantees that rows with identical key values go in the same partition. Partition size is relatively equal if the data within the key column is evenly distributed.Keyless: Rows are distributed independently of data values
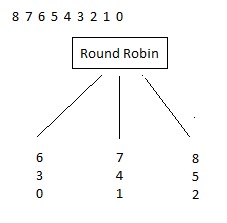 - Round Robin: rows are evenly distributed across partitions. this partitioning method guarantees an exact load balance (the same number of rows processed) between nodes and is very fast. Good for initial import of data if no other partitioning is needed and useful for redistributing data. Round robin assigns rows to partitions like dealing cards. Partition assignment will be the same for a given $APT_CONFIG_FILE.
- Round Robin: rows are evenly distributed across partitions. this partitioning method guarantees an exact load balance (the same number of rows processed) between nodes and is very fast. Good for initial import of data if no other partitioning is needed and useful for redistributing data. Round robin assigns rows to partitions like dealing cards. Partition assignment will be the same for a given $APT_CONFIG_FILE.- Same: existing partitioning remains unchanged. no data is moved between nodes
 - Entire: all rows from a dataset are distributed to each partition. Duplicated rows are stored and the data volume is significantly increased. Each partition gets a complete copy of data. this is useful for distributing lookup and reference data. ENTIRE is the default partitioning for lookup reference links with "Auto" partitioning
- Entire: all rows from a dataset are distributed to each partition. Duplicated rows are stored and the data volume is significantly increased. Each partition gets a complete copy of data. this is useful for distributing lookup and reference data. ENTIRE is the default partitioning for lookup reference links with "Auto" partitioning- Random: rows are randomly distributed across partitions
- Range: an expensive refinement to hash partitioning. It is simillar to hash but partition mapping is user-determined and partitions are ordered. Rows are distributed according to the values in one or more key fields, using a range map (the 'Write Range Map' stage needs to be used to create it). Range partitioning requires processing the data twice which makes it hard to find a reason for using it
Collecting Algorithms
A collector combines partitions into a single sequential stream.
Datastage EE supports the following collecting algorithms:
- Auto: Collect first available record. the default algorithm reads rows from a partition as soon as they are ready. This may lead to producing different row orders in different runs with identical data. The execution is non-deterministic
- Round Robin: picks rows from input partition patiently, for instance: first row from partition 0, next from partition 1, even if other partitions can produce rows faster than partition 1.
- Ordered: reads all rows from first partition, then second partition, then third and so on.
- Sort Merge: produces a globally sorted sequential stream from within partition sorted rows. Sort Merge produces a non-deterministic on un-keyed columns sorted sequential stream using the following algorithm: always pick the partition that produces the row with the smallest key value. Read in by key, presumes data is sorted by the key in each partition, builds a single sorted stream based on the key.
References
1. "Data Stage v8 Essentials Core Modules", IBM, 2009.
2,"Datastage data partitioning and collecting methods", www.etl-tools.info, 2010
No comments:
Post a Comment